

Depuis que le contenu généré par IA a basculé de curiosité technologique à outil industriel, les moteurs de recherche font face à une tension devenue centrale : continuer à organiser le web tout en filtrant une quantité inédite de pages produites à grande vitesse, souvent très proches les unes des autres. La question n’est plus de savoir si l’intelligence artificielle influence la recherche, mais comment elle redessine, en profondeur, les règles de visibilité, de référencement et de distribution du trafic web. Dans les rédactions, chez les e-commerçants ou dans les équipes marketing, l’IA a accéléré la publication ; côté plateformes, elle a obligé les systèmes de classement à mieux distinguer l’utile du répétitif, l’original du copié, le documenté du verbeux.
Ce mouvement est visible dans les évolutions engagées par Google et Microsoft, mais aussi dans l’arrivée d’acteurs nés avec une interface conversationnelle, comme Perplexity. À mesure que la recherche se rapproche d’un “moteur de réponses”, les algorithmes se recalibrent autour d’un enjeu simple en apparence : fournir un résultat pertinent, sourcé et exploitable, même lorsque l’offre de contenus enfle plus vite que la capacité humaine à l’évaluer. Autrement dit, l’adaptation algorithmique n’est pas un ajustement marginal : elle devient la condition pour que la recherche reste praticable.
Une adaptation algorithmique déjà ancrée dans les briques IA de Google
Chez Google, la montée en puissance de l’IA dans la recherche ne date pas d’hier. Des systèmes comme RankBrain ont introduit l’apprentissage automatique pour interpréter des requêtes ambiguës et affiner les résultats en fonction des interactions. Avec BERT, Google a aussi renforcé sa capacité à comprendre le contexte d’une phrase, et donc l’intention réelle derrière une recherche, au-delà de la simple correspondance de mots.
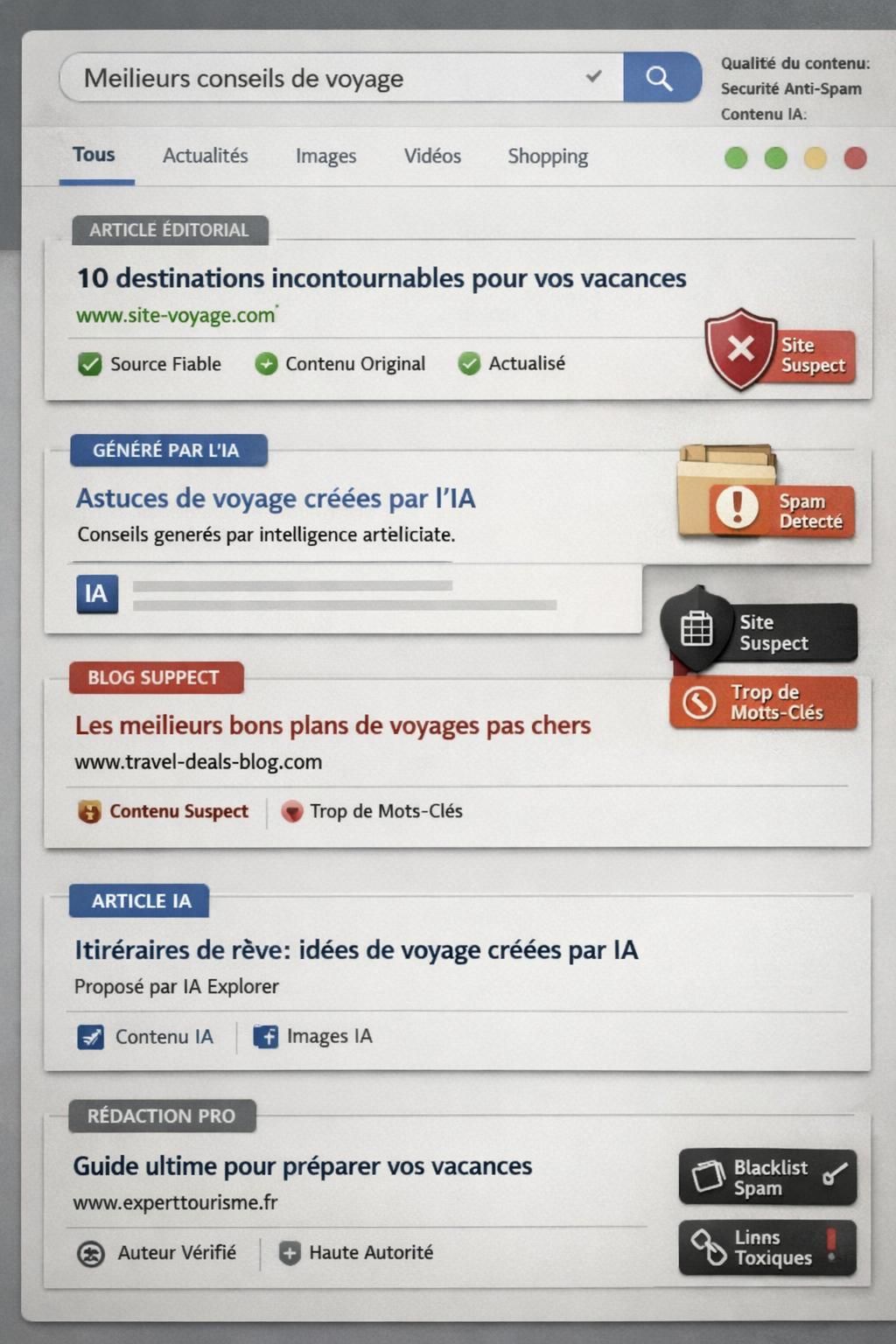
Concrètement, cette orientation pèse directement sur la manière dont les contenus sont évalués. Les pages construites pour “cocher des mots-clés” sans apporter de réponse solide ont davantage de mal à émerger, tandis que les formats qui couvrent un sujet en profondeur, avec une structure lisible et des éléments vérifiables, s’alignent mieux sur l’objectif de pertinence. Cette bascule, souvent résumée à la “qualité”, correspond en réalité à une lecture plus fine : compréhension linguistique, cohérence globale, et capacité à satisfaire la requête.
Dans les services SEO, l’exemple revient régulièrement : une page qui reformule dix articles déjà vus peut encore se positionner temporairement, mais elle devient plus fragile face aux mises à jour et à la concurrence. À l’inverse, un contenu de fond, pensé pour durer et enrichi, résiste mieux aux variations. Sur ce point, les pratiques dites “evergreen” restent un repère, notamment quand elles sont articulées avec l’actualité et des mises à jour régulières, comme l’illustre l’approche du contenu evergreen pour les entrepreneurs. Le signal envoyé est clair : la production massive ne suffit plus, il faut démontrer une valeur réelle.
La lutte contre le spam s’intensifie face à l’industrialisation du contenu généré par IA
L’un des effets immédiats de la généralisation du contenu généré par IA est la hausse mécanique du bruit : pages dupliquées, variantes quasi identiques, textes longs mais pauvres en information, ou sites montés pour capter un volume de requêtes à faible concurrence. Cette dérive n’est pas nouvelle, mais l’automatisation l’a rendue plus rapide et moins coûteuse, ce qui oblige les plateformes à renforcer la lutte contre le spam.
Les moteurs disposent désormais de modèles capables d’identifier des patterns typiques : répétitions, incohérences, absence de sources, ou promesses éditoriales non tenues. Surtout, l’analyse s’appuie de plus en plus sur des signaux comportementaux : taux de clic, retour rapide à la page de résultats, temps passé, navigation interne. Autrement dit, la sanction n’est pas uniquement “textuelle”, elle passe aussi par la mesure de l’expérience réelle.
Un cas fréquemment observé dans les équipes de croissance : un site qui publie des dizaines de pages par jour voit parfois son indexation progresser… puis stagner, tandis que la visibilité se dégrade lorsque les pages n’obtiennent pas d’engagement ou se cannibalisent entre elles. L’algorithme n’a pas besoin de “deviner” l’origine IA ; il constate surtout une faible utilité et un signal utilisateur décevant. Cette logique met la qualité de contenu au centre, non comme slogan, mais comme mécanisme de classement.
Cette bataille pour la visibilité touche aussi les médias et les éditeurs, notamment via les carrefours de distribution. Les enjeux autour de Google News, entre dépendance au trafic et règles de sélection, illustrent cette tension, comme le montre l’analyse des leviers de visibilité des éditeurs sur Google News. Quand les formats de réponse se densifient et que les flux s’accélèrent, les filtres deviennent plus stricts, et l’originalité éditoriale redevient un avantage compétitif.
Dans ce contexte, l’IA agit comme un révélateur : elle facilite la production, mais met aussi en lumière ce qui n’apporte rien de neuf. La question qui se pose aux éditeurs n’est plus “combien publier”, mais “qu’est-ce qui mérite d’être découvert”.
De nouvelles interfaces de recherche bousculent le référencement et le trafic web
Au-delà des filtres, l’autre changement majeur concerne la forme même de la recherche. Microsoft a accéléré l’intégration de modèles de type ChatGPT dans Bing dès 2023, ouvrant la voie à une interaction conversationnelle où l’utilisateur enchaîne des questions, demande des précisions et attend une synthèse. Dans le même temps, des acteurs comme Perplexity se sont positionnés sur une promesse proche : répondre, citer des sources, maintenir le contexte.
Pour le référencement, cette évolution déplace une partie de la valeur : apparaître dans une liste de liens reste crucial, mais la place gagnée dans une réponse synthétique, ou dans une citation de source, devient un autre terrain de compétition. Les contenus structurés, documentés, et faciles à “ingérer” par des systèmes de synthèse prennent un avantage. Les données structurées (comme schema.org) participent à ce mouvement en clarifiant le contexte : auteur, date, type de contenu, entités mentionnées.
Dans les entreprises, cela se traduit par une réorganisation des stratégies de distribution. Les newsletters, par exemple, sont redevenues un canal de stabilisation face aux variations des plateformes : elles sécurisent une audience et réduisent la dépendance à un seul flux de trafic. Le phénomène est détaillé dans l’analyse sur la multiplication des newsletters et leur monétisation, qui montre comment certains acteurs tentent de compenser l’imprévisibilité des algorithmes.
Cette évolution technologique a un effet concret : le web se lit davantage à travers des couches de synthèse. Pour rester visibles, les sites doivent à la fois produire du neuf et être compris sans ambiguïté par des systèmes de classement et de génération. À l’heure du volume, la différenciation redevient la stratégie la plus rationnelle.






